Static analysis of an unknown compression format
I really enjoy reverse engineering stuff. I also really like playing video games. Sometimes, I get bored and start wondering how the video game I’m playing works internally. Last year, this led me to analyze Tales of Symphonia 2, a Wii RPG. This game uses a custom virtual machine with some really interesting features (including cooperative multithreading) in order to describe cutscenes, maps, etc. I started to be very interested in how this virtual machine worked, and wrote a (mostly) complete implementation of this virtual machine in C++.
However, I recently discovered that some other games are also using this same virtual machine for their own scripts. I was quite interested by that fact and started analyzing scripts for these games and trying to find all the improvements between versions of the virtual machine. Three days ago, I started working on Tales of Vesperia (PS3) scripts, which seem to be compiled in the same format as I analyzed before. Unfortunately, every single file in the scripts directory seemed to be compressed using an unknown compression format, using the magic number “TLZC”.
Normally at this point I would have analyzed the uncompress function dynamically using an emulator or an on-target debugger. However, in this case, there is no working PS3 emulator able to help me in my task, and I also don’t possess an homebrew-enabled PS3 to try to dump the game memory. Sadface. I tend to prefer static analysis to dynamic analysis, but I also didn’t know a lot about compression formats at this point. Still, I started working on reversing that format statically.
I started by decrypting the main game executable (thanks, f0f!) to check if I could find the uncompress function in the binary. Unluckily, cross-references did not help me find anything, and immediate values search (in order to find the FOURCC) did not lead me to anything. I was stuck with 500 compressed files and a binary where I was not able to find the interesting code.
Oh well. Let’s start by analyzing the strings in this binary:
$ strings eboot.elf | grep -i compr
Warning: Compressed data at address 0x%08X is *bigger* than master data (%d > %d). Pointless?
Warning: Compressed data at address 0x%08X is *bigger* than master data (%d > %d). Pointless?
The file doesn't contain any compressed frames yet.
EDGE ZLIB ERROR: DecompressInflateQueueElement returned (%d)
unknown compression method
EDGE ZLIB ERROR: Stream decompressed to size different from expected (%d != %d)
EDGE LZMA ERROR: Size of compressed data is %d. Maximum is %d.
EDGE LZMA ERROR: Size of uncompressed data is %d. Maximum is %d.
EDGE LZMA ERROR: DecompressInflateQueueElement returned (%d)
*edgeLzmaInflateRawData error: compressed bytes processed (0x%x) is not value expected (0x%x)
*edgeLzmaInflateRawData error: uncompressed bytes processed (0x%x) is not value expected (0x%x)
We have references to an LZMA decompression library as well as zlib. However, if we compare a TLZC header to some zlib’d data and an LZMA header, they do not really look alike:
TLZC:
0000000: 544c 5a43 0104 0000 ccf0 0f00 80d4 8300 TLZC............
0000010: 0000 0000 0000 0000 5d00 0001 0052 1679 ........]....R.y
0000020: 0e02 165c 164a 11cf 0952 0052 0052 0052 ...\.J...R.R.R.R
ZLIB:
0000000: 789c d4bd 0f7c 54d5 993f 7cee dc49 3281 x....|T..?|..I2.
0000010: 58c6 766c 8306 3211 dc4d 809a d8d2 76c2 X.vl..2..M....v.
0000020: 4032 51ec 3b48 94e9 fb0b 6bb4 b424 12bb @2Q.;H....k..$..
LZMA:
0000000: 5d00 0080 00ff ffff ffff ffff ff00 3f91 ].............?.
0000010: 4584 6844 5462 d923 7439 e60e 24f0 887d E.hDTb.#t9..$..}
0000020: 86ff f57e 8426 5a49 aabf d038 d3a0 232a ...~.&ZI...8..#*
Looking further into the TLZC header though, there is something that looks very
interesting: the 5D 00 00 01 00 string is almost like the 5D 00 00 80 00
string from the LZMA header. Looking at some LZMA format
specification
I was able to figure out that 5D is a very classic LZMA parameters value. It
is normally followed by the dictionary size (in little endian), which by
default is 0x00800000 with my LZMA encoder but seems to be 0x00010000 in
the TLZC file. The specification tells us that this value should be between
0x00010000 and 0x02000000, so the TLZC value is in range and could be
valid.
My first try was obviously to try to reconstruct a valid LZMA header (with a very big “uncompressed size” header field) and put it in front of the TLZC data (header removed):
lzma: test.lzma: Compressed data is corrupt
Sadface. Would have been too easy I guess.
Let’s take a closer look at the TLZC header:
- Bytes
0 - 4: FOURCC"TLZC" - Bytes
4 - 8: unknown (maybe some kind of version?) - Bytes
8 - 12: matches the size of the compressed file - Bytes
12 - 16: unknown but might be the size of the uncompressed file: for all of the 500 files it was in an acceptable range. - Bytes
16 - 24: unknown (all zero) - Bytes
24 - 29: probably LZMA params
Stuck again with nothing really interesting. I started looking at random parts of the file with an hexadecimal editor in order to notice patterns and compare with LZMA. At the start of the file, just after the header, the data seem to have some kind of regular structure that a normal LZMA file does not have:
0000040: 1719 131f 1f92 2480 0fe6 1b05 150b 13fd ......$.........
0000050: 2446 19d0 1733 17b4 1bf8 1f75 2052 0b5c $F...3.....u R.\
0000060: 1123 11a0 0fe2 149b 1507 0d5e 1a5f 1347 .#.........^._.G
0000070: 18ca 213f 0e1e 1260 1760 158c 217d 12ee ..!?...`.`..!}..
0000080: 122b 17f7 124f 1bed 21d1 095b 13e5 1457 .+...O..!..[...W
0000090: 1644 23ca 18f6 0c9f 1aa1 1588 1950 23a9 .D#..........P#.
00000a0: 06c1 160b 137c 172c 246a 1411 0e05 1988 .....|.,$j......
In this range there are a lot of bytes in [0x00-0x20] each followed by a byte
in [0x80-0xFF]. This is quite different from the start of a normal LZMA file,
but at that point that doesn’t help us a lot.
This made me think of entropy. If I was able to measure the frequency of each
byte value in the file maybe I could compare it to some other compression
format or notice something. I created a simple Python file which counts the
occurrences of each byte value. For single byte values, this did not give any
interesting results: max count is 4200 and min count is 3900, no notable
variation, etc. However, looking at the byte digrams showed me something very
interesting: the 00 7F digram occurred 8 times more than most digrams, and
the 00 00 digram twice as much. I followed this lead and looked at what bytes
where next after 00 7F:
00 7F 9Foccurs 4x more than all other digrams00 7F 9F 0Cis the only substring that starts with00 7F 9F- Next byte is almost always
C6but in very few casesA6also occurs - After that, the next byte is between
0x78and0x7C, most of the time either7Bor7C - No statistical evidence of a byte occurring more than the others after this.
In a 8MB file, the string 00 7F 9F 0C C6 7B occurred exactly 25 times. That’s
a lot, but short strings like this do not really give us any big information. I
started to look at the 00 00 digram after that and got something a lot more
interesting: a very long repeating sequence. In the file I was analyzing, this
0x52 bytes sequence appeared 3 times in a row:
0000000: 0000 7fb6 1306 1c1f 1703 fe0f f577 302c .............w0,
0000010: d378 4b09 691f 7d7a bc8e 340c f137 72bc .xK.i.}z..4..7r.
0000020: 90a2 4ee7 1102 e249 c551 5db6 1656 63f2 ..N....I.Q]..Vc.
0000030: edea b3a1 9f6d d986 34b3 f14a f52b 43be .....m..4..J.+C.
0000040: 1c50 94a5 747d 40cf 85ee db27 f30d c6f7 .P..t}@....'....
0000050: 6aa1 j.
I tried to discern some kind of patterns in these data, tried to grep some of the files on my system to find parts of this sequence, no luck. Stuck again.
After a long night, I came back to my notes and remembered the start of the
file where there were strange byte patterns. If I started at offset 59 and took
2 bytes little endian integers from there, each of these integers was less than
0x2000, and often in the same range. But more interesting than that fact:
there was three consecutive integers equal to 0x0052, the size of the three
times repeating block I noticed earlier.
That’s when I got the idea that ultimately solved this puzzle: TLZC files are not one big compressed block, but several blocks, each compressed individually. The size of these compressed blocks is contained in the header. That’s actually a very common structure used to allow semi-random access in a compressed file: you don’t need to uncompress the whole file but only the part of the file which contains the data you want. It seemed to make a lot of sense, so I went with it and tried to find evidence that failed my hypothesis.
If this file is indeed compressed by block, there must be somewhere in the header either the number of blocks and their size, either the full size of the uncompressed file and the blocks size. I went back to the TLZC header, and more precisely to the field that I thought (without a lot of evidence) to be the uncompressed file size. To confirm that it was it, I tried computing the compression ratio of all of the files using the compressed size and the uncompressed size. It gave me a plot like this:
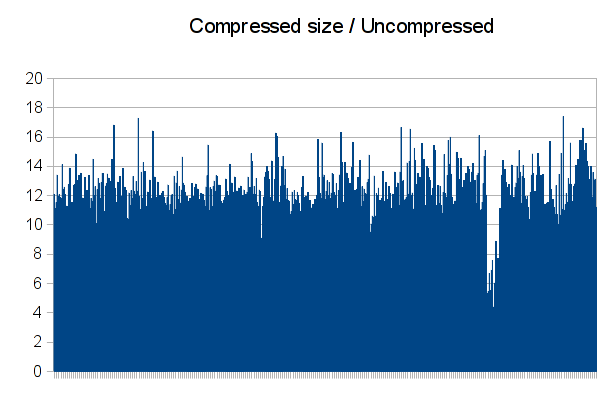
That confirms my theory: there is a bit of noise and some files compressed a bit more than the others, but this is still almost constant. We now have the size of each uncompressed file, we’re just missing the size of an uncompressed block.
If each block is independently compressed as I assumed, taking the 0x52 sized
block from above and uncompressing it should get us some results. Fail: after
adding an LZMA header, trying to uncompress the file still fails at the first
bytes of the block. Sadface again. But, thinking about it, we may know that the
block size is 0x52 but we never confirmed where exactly it started! I
generated all possible rotations of this block, and tried uncompressing each
one:
lzma: rot0.bin.test.lzma: Compressed data is corrupt
lzma: rot1.bin.test.lzma: Unexpected end of input
lzma: rot2.bin.test.lzma: Compressed data is corrupt
lzma: rot3.bin.test.lzma: Compressed data is corrupt
lzma: rot4.bin.test.lzma: Compressed data is corrupt
lzma: rot5.bin.test.lzma: Compressed data is corrupt
F. Yeah. We finally uncompressed something which seems valid, but now LZMA
can’t find the input end marker and deletes the output file. Using strace, I
can see that the output was exactly 0x10000 bytes before it was unlinked:
write(2, "lzma: ", 6lzma: ) = 6
write(2, "rot1.bin.test.lzma: Unexpected e"..., 43) = 43
write(2, "\n", 1
) = 1
close(4) = 0
lstat("rot1.bin.test", {st_mode=S_IFREG|0600, st_size=65536, ...}) = 0
unlink("rot1.bin.test") = 0
Let’s try putting the size in the LZMA header instead of letting the decoder
figure out the size (there is an optional “size” field in the LZMA header). As
expected, it works just fine and the uncompressed file is 0x10000 bytes long.
The data in it is obviously a bit repetitive (compressed to 52 bytes…) but
seems coherent (looks like part of an ARGB image to me):
0000000: ffd8 b861 ffd8 b861 ffd8 b861 ffd8 b861 ...a...a...a...a
0000010: ffd8 b861 ffd8 b861 ffd8 b861 ffd8 b861 ...a...a...a...a
0000020: ffd8 b861 ffd8 b861 ffd8 b861 ffd8 b861 ...a...a...a...a
0000030: ffd8 b861 ffd8 b861 ffd8 b861 ffd8 b861 ...a...a...a...a
0000040: ffd8 b861 ffd8 b861 ffd8 b861 ffd8 b861 ...a...a...a...a
0000050: ffd8 b861 ffd8 b861 ffd8 b861 ffd8 b861 ...a...a...a...a
At that point I could almost uncompress the whole file, but we don’t know where
the blocks data start in the file because we don’t know how much blocks there
are. To test a bit more the decompressing process, I tried taking the block
just before the first 0x52 block: I can see in the block size table at the
start of the file that its size is 0x9CF, so it must start at offset 0x6415
in the file (because the 0x52 block was at offset 0x6D67). Extracting it
works too, and its size is also 0x10000. It seems to be part of the same ARGB
image (being just before, it was kind of obvious), but less repetitive this
time:
0000000: fffe da9e fffe de9e fffa da9e ff86 7457 ..............tW
0000010: ff66 3232 ffc6 5252 ffc6 5252 ffc3 5151 .f22..RR..RR..QQ
0000020: ffc3 5151 ffc3 5151 ffc3 5151 ffc3 5151 ..QQ..QQ..QQ..QQ
0000030: ffc3 5151 ffc3 5151 ffc3 5151 ffc3 5151 ..QQ..QQ..QQ..QQ
0000040: ffc3 5151 ffc3 5151 ffc3 5151 ffc3 5151 ..QQ..QQ..QQ..QQ
0000050: ffc3 5151 ffc3 5151 ffc3 5151 ffc3 5151 ..QQ..QQ..QQ..QQ
From there I uncompressed a few other blocks around the 0x52 block, and each
of these blocks was 0x10000 bytes long. I assumed that it was some kind of
constant size. From there, we can easily get the number of blocks in the file:
just take the uncompressed file size, divide it by the block size we just found
(rounding correctly!) and here is your number of blocks!
For the first file, uncompressed size is 8639616, which means 132 blocks
are required. This means that the first block data is at offset:
header_size (1D) + number_of_blocks * sizeof (uint16_t)
Uncompressing that first block gives us something interesting that validates everything we’ve done so far:
0000000: 4650 5334 0000 0006 0000 001c 0000 0080 FPS4............
0000010: 0010 0047 0000 0000 0000 0000 0000 0080 ...G............
0000020: 0000 f280 0000 f204 0000 0000 0000 f300 ................
0000030: 0000 0e00 0000 0d90 0000 0000 0001 0100 ................
0000040: 007c 6c00 007c 6c00 0000 0000 007d 6d00 .|l..|l......}m.
0000050: 0000 0600 0000 059a 0000 0000 007d 7300 .............}s.
The FPS4 FOURCC is an archiving format commonly used in Tales of games.
That means we actually uncompressed valid stuff and not only garbage!
From there, it’s easy to write a full decompression software. Here is mine, written in Python using PyLZMA:
import mmap
import os
import pylzma
import struct
import sys
UNCOMP_BLOCK_SIZE = 0x10000
def decompress_block(params, block, out, size):
block = params + block
out.write(pylzma.decompress(block, size, maxlength=size))
def decompress_tlzc(buf, out):
assert(buf[0:4] == "TLZC")
comp_size, uncomp_size = struct.unpack("<II", buf[8:16])
num_blocks = (uncomp_size + 0xFFFF) / UNCOMP_BLOCK_SIZE
lzma_params = buf[24:29]
block_header_off = 29
data_off = block_header_off + 2 * num_blocks
remaining = uncomp_size
for i in xrange(num_blocks):
off = block_header_off + 2 * i
comp_block_size = struct.unpack("<H", buf[off:off+2])[0]
block = buf[data_off:data_off+comp_block_size]
data_off += comp_block_size
if remaining < UNCOMP_BLOCK_SIZE:
decompress_block(lzma_params, block, out, remaining)
else:
decompress_block(lzma_params, block, out, UNCOMP_BLOCK_SIZE)
remaining -= UNCOMP_BLOCK_SIZE
if __name__ == "__main__":
fd = os.open(sys.argv[1], os.O_RDONLY)
buf = mmap.mmap(fd, 0, prot=mmap.PROT_READ)
decompress_tlzc(buf, open(sys.argv[2], "w"))
os.close(fd)
Three days of work for 40 lines of Python. So worth it!
This was a very interesting experience for someone like me who did not know a lot about compression formats: I had to look a lot into LZMA internals, read tons of stuff about how it works to try to find some patterns in the compressed file, and found out that the most simple methods (trying to find repeating substrings) give actually a lot of interesting results to work with. Still, I hope next time I work on such compression algorithm I’ll have some code to work with or, even better, an emulator!