NDH2K13 misc400 writeup: OMG, electronics…
Found some information about what seems to be an OTP. And a webpage asking
for a valid token. The design draft we retrieved looks terrible, they must
have got it fixed, yet the algorithm should be similar.
Score 400
Link http://z0b.nuitduhack.com:8001/
The goal of this exercise was to understand the given electronic schematic of a One-time-password generator. This device generates new unique passwords at a fixed time interval. Two tokens were also given as part of the challenge’s instructions, with the time they were generated so the goal was to get the algorithm used by the device to generate a new token from the previous one, to find the generation frequency and so to deduce what the token is at the current time.
We translated the diagram into a python script to easily generate as many token as we wanted.
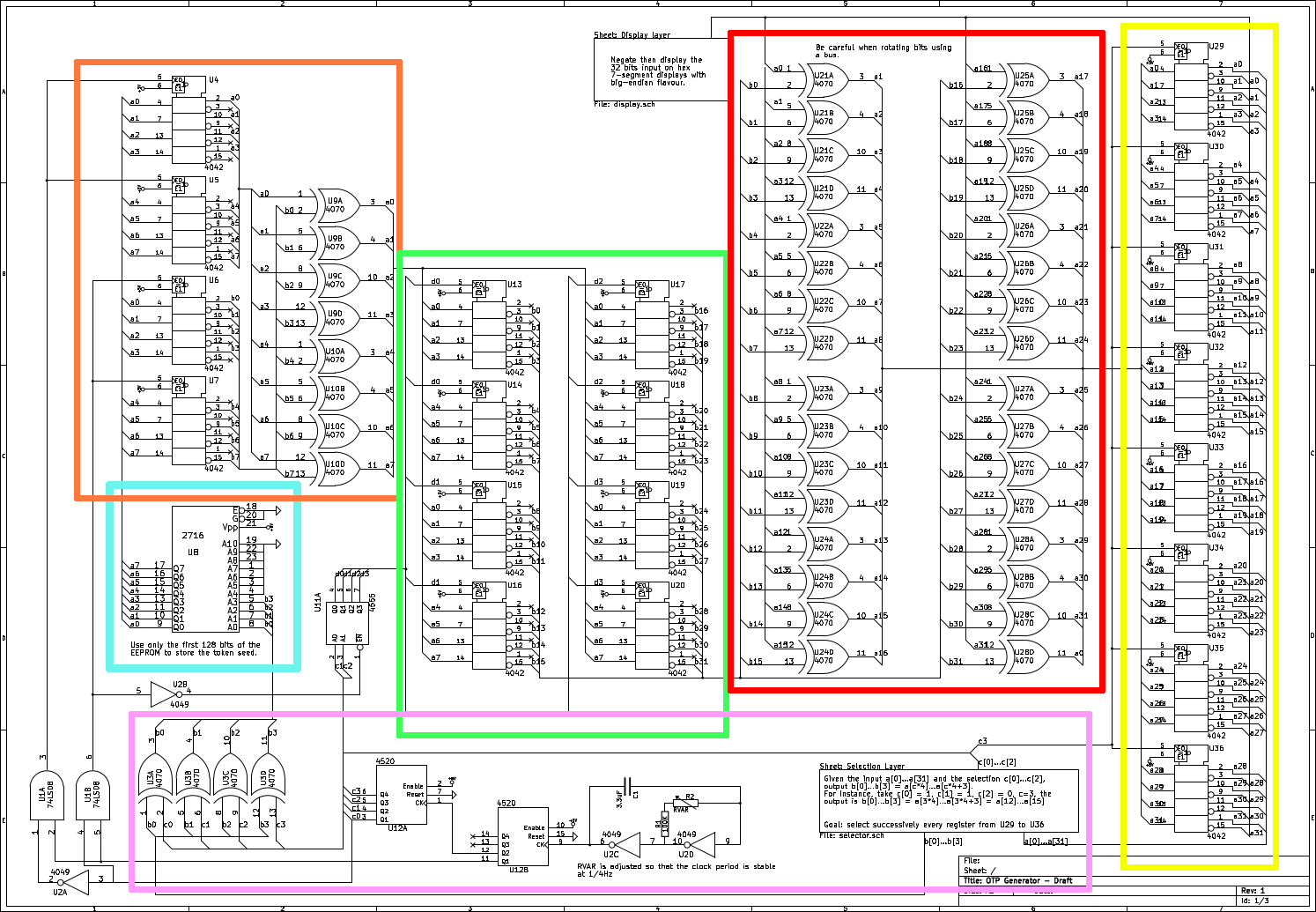
The circuit diagram
Okay, so let’s break down this circuit, it’s not that complicated, the tokens are just 32 bits long.
The first part, in yellow simply stores the token that is currently displayed by the device in eight differents 4-bits flip-flops. It is important to note, as written on the diagram, that the 7-segments display negates its input before displaying it, so the wire at the top of the diagram is the complement of the token. The wires that go to the pink block (a0-a31) are the token itself.
The next block, the pink one, uses the previous token to compute the address of the byte sent to the next block. The selector, on the right, extracts four by four the token bytes, which will be xored with the value of a simple counter.
def compute_addr_from_previous_token(previous_token):
"""The Pink Block
Return in order the list of
computed addresses from the previous token
"""
addrs = []
for count in range(8):
#Extract the 4 lowest bytes of the token
v = previous_token & 0xf
previous_token >>= 4
#Xor with the counter value
addr = v ^ count
addrs.append(addr)
assert previous_token == 0
return addrs
The generated address is then used, in the blue block, to read the seed value (also given in the instructions) at the computed offset, one byte at a time. This byte is then stored in two of the 4-bits flip-flops in the orange block, either in the two flip-flops at the top of the block or at the bottom, every two cycles. These two bytes are xored together, after their 4 higher bits were complemented.
# From the instructions
seed = "025EF87E7819E3A3B48E92CD92E7AB35"
def extract_from_eeprom(addr):
if addr > 15:
raise ValueError("SEED BAD ADDR : {0}".format(addr))
data = seed[addr * 2 : (addr + 1) * 2].decode('hex')
return ord(data)
def get_eeprom_value_from_addr(addrs):
"""The blue Block"""
values = []
for addr in addrs:
values.append(extract_from_eeprom(addr))
return values
def compute_2byte(b1, b2):
"""The Orange Block"""
v1 = (b1 & 0xf) | ((0xff ^ b1) & 0xf0)
v2 = (b2 & 0xf) | ((0xff ^ b2) & 0xf0)
return v1 ^ v2
This new value is stored in the green block in four groups of two 4-bits flip-flops, and the previous operation is repeated four times to compute a final 4-bytes value.
def stock_intermediate_state(values):
"""The green block: stocks 4 bytes and use it as a Dword after. Translated
by taking a list of 4 bytes and outputing the complement as an int."""
result = 0
#Low byte is first
for v in reversed(values):
result = (result << 8) + v
return 0xffffffff ^ result
The complemented value of the token is xored with the complement of this new value. This result is rotated by one to the right (rotation that we didn’t see for our first implementation, despite the fact that it was clearly written at the top…), stored in the yellow block as seen a the top of the article and displayed.
def apply_xor_with_previous(previous_token, interm_dword):
""" The red block: Xor the internal DWORD with:
NOT previous_token and rotate 1 the result """
not_previous_token = 0xffffffff ^ previous_token
xored = not_previous_token ^ interm_dword
#Rotation
rot = (xored & 0x80000000)
if rot:
rot = 1
new_token = ((xored << 1) & 0xffffffff) | rot
return new_token
The final code is available at the bottom of the article.
Now that we had our algorithm in Python, with the reference tokens given in the instructions, we could compute any token we wanted. We computed the number of tokens that separated the two given tokens and thus could find the index of the token at any given date after the first given token.
We used WolframAlpha to avoid messing-up timezones and timedeltas (we were traumatized by Codegate…) for the time computation. We computed the token at the index we thought but it didn’t work, then tried the 5 tokens below and above it but it didn’t work either. Okay, maybe they screwed the timezone, try the tokens one hour before and after, nope. Okay, you know what? screw this, compute 100 values before and 100 after the tokens and:
for tok in `python2 elec.py | tail -200 | cut -d '-' -f 2`; do
curl "http://z0b.nuitduhack.com:8001/?token=$tok" | grep 'Wrong token.'
if [ "$?" -eq 1 ]; then echo FOUUUUUND: $tok; break; fi
done
And it worked, so I guessed we made a mistake in our computations of time-deltas.
#!/usr/bin/python2
seed = "025EF87E7819E3A3B48E92CD92E7AB35"
previous_token = 0x0FDE45E3
def extract_from_eeprom(addr):
if addr > 15:
raise ValueError("SEED BAD ADDR : {0}".format(addr))
data = seed[addr * 2 : (addr + 1) * 2].decode('hex')
return ord(data)
def get_eeprom_value_from_addr(addrs):
"""The blue block"""
values = []
for addr in addrs:
values.append(extract_from_eeprom(addr))
return values
def compute_2byte(b1, b2):
"""The orange block"""
v1 = (b1 & 0xf) | ((0xff ^ b1) & 0xf0)
v2 = (b2 & 0xf) | ((0xff ^ b2) & 0xf0)
return v1 ^ v2
def compute_addr_from_previous_token(previous_token):
"""The pink block
Returns in order the list of
computed addresses from the previous token
"""
addrs = []
for count in range(8):
#Extract the 4 lowest bytes of the token
v = previous_token & 0xf
previous_token >>= 4
#Xor with the counter value
addr = v ^ count
addrs.append(addr)
assert previous_token == 0
return addrs
def stock_intermediate_state(values):
"""The green block: stocks 4 bytes and use it as a Dword after. Translated
by taking a list of 4 bytes and outputing the complement as an int."""
result = 0
#Low byte is first
for v in reversed(values):
result = (result << 8) + v
return 0xffffffff ^ result
def apply_xor_with_previous(previous_token, interm_dword):
""" The red block: Xor the internal DWORD with:
NOT previous_token and rotate 1 the result """
not_previous_token = 0xffffffff ^ previous_token
xored = not_previous_token ^ interm_dword
#Rotation
rot = (xored & 0x80000000)
if rot:
rot = 1
new_token = ((xored << 1) & 0xffffffff) | rot
return new_token
def next_token(previous_token):
#Addrs computed by pink part
addrs = compute_addr_from_previous_token(previous_token)
#Send addr to the eeprom
values = get_eeprom_value_from_addr(addrs)
#The Orange part take bytes 2-by-2 and outpur just one byte
interm_byte = []
for i in range(4):
v1, v2 = values[i * 2 : (i + 1) * 2]
interm_byte.append(compute_2byte(v1, v2))
#The green block just stock intermediate computed byte
#and NOT them in order to use them as a DWORD
interm_dword = stock_intermediate_state(interm_byte)
#The Red Block output the new token
new_token = apply_xor_with_previous(previous_token, interm_dword)
return new_token
gen_per_min = (314.0/1346)
diff_min = 72348
diff = int(gen_per_min * diff_min)
for i in xrange(diff + 100):
previous_token = next_token(previous_token)
if previous_token == 0x7113aad3:
print "FOUND: " + str(i) + " - " + hex(previous_token)
if diff - 100 <= i <= diff + 100:
print str(i) + " : " + "{0:08x}".format(previous_token)