Getting back determinism in the Low Fragmentation Heap
Introduction
The Low Fragmentation Heap is the Front End allocator for the userland in modern
Windows OS. It has been introduced in 2001 in Windows XP and is used by default
since Windows Vista.
Microsoft has introduce a lot of new mitigations in response to generic attack
against the LFH since its first disclosure in Windows XP. One of them,
introduced in Windows 8, is the non-determinism of the allocation. This
mitigation has quite a lot of consequences because it will break most of the
overflows exploits but also use-after-free exploits.
Low Fragmentation Heap
The goal of the Low Fragmentation Heap is, as its names says, to reduce the fragmentation. It is not a different heap but a different policy. Here is a global overview of how the allocation is made by Windows:
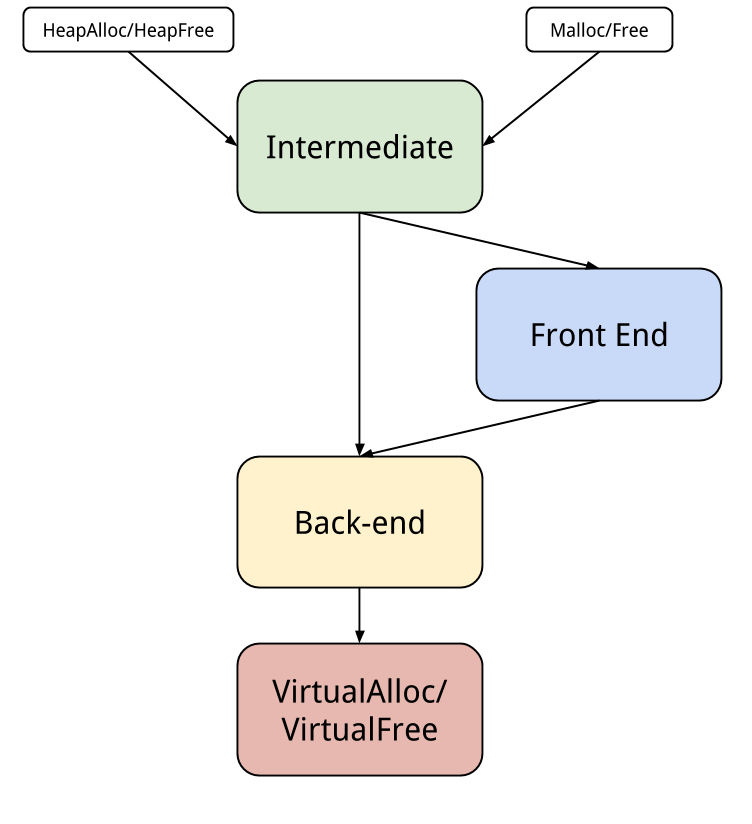
The HeapAlloc and HeapFree functions will make some tests and decide if it should call the back-end or the front-end, which means the LFH since the removal of the Look-Aside-List. There are some conditions for an allocation to be made by the LFH:
- The size must be inferior to 0x4000 bytes
- The LFH must be activated for this heap. It is possible to deactivate the LFH in a heap by setting HEAP_NO_SERIALIZE when creating a heap with HeapCreate.
- The LFH must be activated for this allocation. It is also possible to deactivate the LFH for a particular allocation (still with HEAP_NO_SERIALIZE).
- There must be enough allocation for activating the LFH for this size.
The function charge of the allocation for the LFH is
RtlpLowFragHeapAllocFromContext and the one for the back-end is
RtlpAllocateHeap which will use the VirtualAlloc from the system.
If you want more details about how the LFH works, you can look at my presentation in french about this subject during the lse summer week 2014, or read the excellent paper Windows 8 Heap Internals by Chris Valasek and Tarjei Mandt.
Mitigation
Microsoft has introduced two factors of randomization with Windows 8. The first one is to add a random offset for each virtual allocation, its primary goal is removing the predictability of heap metadata for preventing their corruption. The second is for randomizing the UserBlock returned by an allocation.
Before those changes, a simple code like this:
#include <Windows.h>
#include <stdio.h>
#include <iostream>
int main()
{
HANDLE hHeap = GetProcessHeap();
int i = 0;
int size = 0x40;
LPVOID chunk;
// lfh activation
while (i < 0x10)
{
chunk = HeapAlloc(hHeap, 0, size);
i++;
}
chunk = HeapAlloc(hHeap, 0, size);
printf("\n\nchunk1: %p\n", chunk);
HeapFree(hHeap, 0, chunk);
chunk = HeapAlloc(hHeap, 0, size);
printf("\n\nchunk2: %p\n", chunk);
HeapFree(hHeap, 0, chunk);
}
would give us an output which is predictable and will allow us to trigger a simple use-after-free:
chunk1: 011D8CC0
chunk2: 011D8CC0
The same code since Windows 8 will give us this result:
chunk1: 011D8CC0
chunk2: 011D8DE0
We can clearly see that the result is not easily predictable anymore. The next
question is how is this implemented ?
The implementation is pretty simple, in RtlpCreateLowFragHeap there is a call
to RtlpInitializeLfhRandomDataArray:
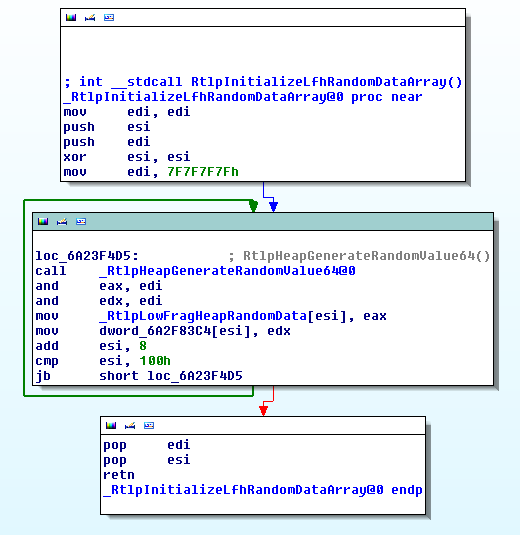
It will basically fill the RtlpLowFragHeapRandomData array with 0x100 random
values. This array will then be used with a value called LowFragHeapDataSlot
from the TEB (Thread Environment Block) which is use for storing value by
thread.
mov ecx, large fs:18h ; getting the current TEB
movzx esi, word ptr [ecx+0x0FAA] ; getting LowFragHeapDataSlot
lea eax, [esi+1] ; adding 1 to LowFragHeapDataSlot
and eax, 0xff ; checking we don't go past the 0x100
mov [ecx + 0x0faa], ax ; rewrite LowFragHeapDataSlot + 1
movzx eax, byte ptr RtlpLowFragHeapRandomData[esi] ; getting the value at offset of LowFragHeapDataSlot
This value is then used with a ror on the bitmap to determine the position where to start, and from this position it will look for the first free block in the bitmap which will allow to make two consecutive allocations to not be at predictable place.
Attacks
In 2008 at ruxcon, Ben Hawkes presented Attacking the Vista Heap in its
slides he made several claims and more precisely : Application specific attacks
are the future. This is probably more true than ever with a heap implementation
like the one we get since Windows 8 and the non-determinism of the allocation is
a big problem even for application specific attacks. This mitigations has been
well documented but I haven’t found any documentation about how to bypass it.
First attack
The first basic attack we can think of is the idea to fill all the slots except one with the object we want to overwrite. We then fill the last slot remaining with the object in which we can overwrite.

This technic will work perfectly for use-after-free because we don’t care about the data locate right before or right after it. On the contrary for a classic overflow we really care about what is after (I don’t consider underflow but it is basically the same principle). If you control the whole userblock you have fair chances of success: the only case for which it will not work is if we get the last chunk.
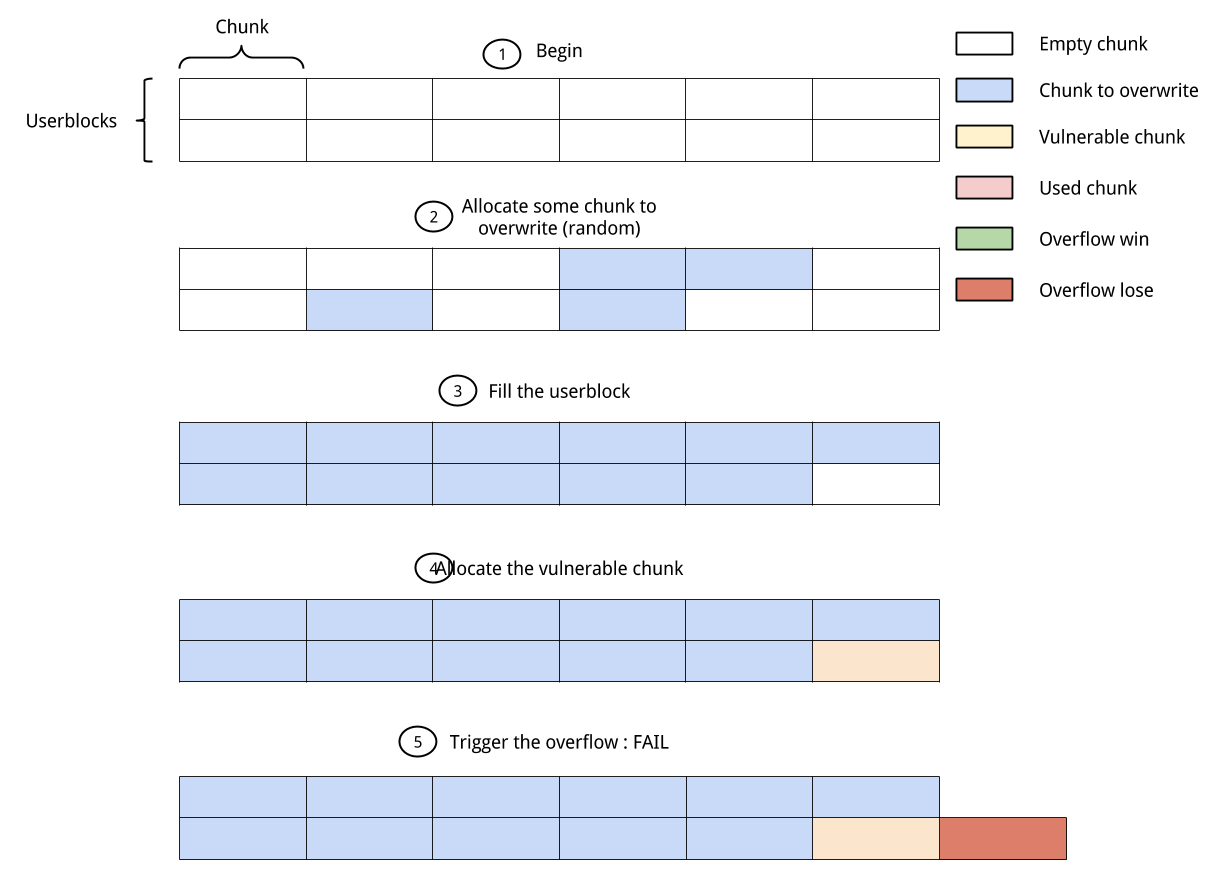
But if there is some allocations made for the user blocks the probability of success will decrease a lot because you have more position which will end with a failure.
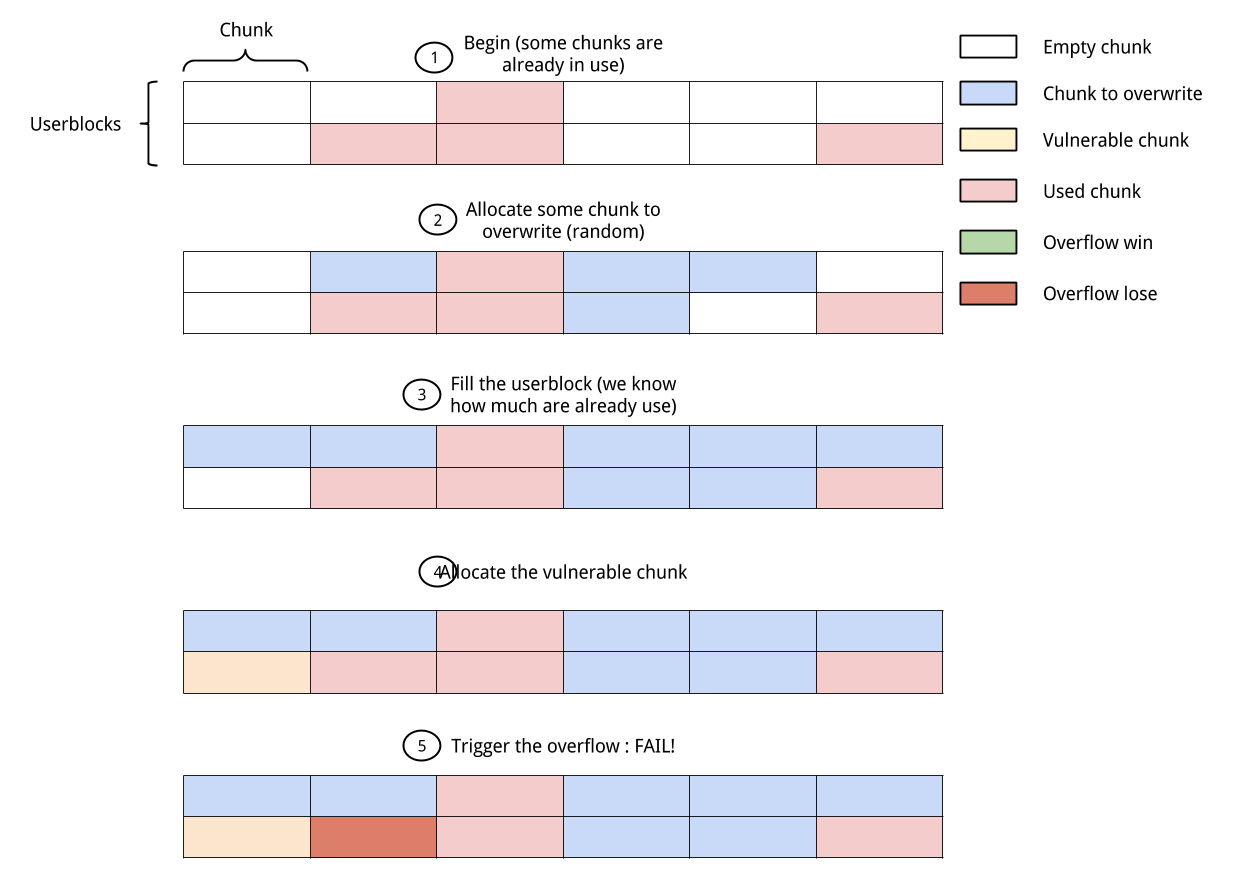
It also means that you need to be able to allocate enough time the data you want to overflow which could not be the case and in the end you will not be able to know which one you overflowed so you will need a way to test this.
Second attack
In the mitigation part we saw that for getting a random value the
RtlpLowFragHeapAllocFromContext function take a value from the pre-populated
RtlpLowFragHeapRandomData array. This array is changed in only two occasions:
- in the
RtlpInitializaLfhRandomDataArrayfunction when creating the LFH - in the
RtlpSubSegmentInitializefunction which is called byRtlpLowFragHeapAllocFromContextwhen a subsegment needs initialization So basically this array is not re-populated often, and we can make allocation without the array being changed. The counter is stored in the TEB and is incremented after each use of the array. Since the counter must stay inferior to array’s size, a modulo 0x100 is made. That means that we can just make 0xff allocations and going back to the same position in the array. The following code will allow us to get twice the same chunk:
#include <Windows.h>
#include <stdio.h>
#include <iostream>
int main()
{
HANDLE hHeap = GetProcessHeap();
char c;
int i = 0;
int size = 0x40;
LPVOID chunk;
// activating the LFH for the size we choose
while (i < 0x10)
{
chunk = HeapAlloc(hHeap, 0, size);
i++;
}
// making the allocation we want
chunk = HeapAlloc(hHeap, 0, size);
printf("chunk: %p\n", chunk);
HeapFree(hHeap, 0, chunk);
// making 0xff allocation for getting back
// to the same point in the RtlpLowFragHeapRandomData
i = 0;
while (i < 0x100 - 1)
{
chunk = HeapAlloc(hHeap, 0, size);
HeapFree(hHeap, 0, chunk);
i++;
}
// reallocating : we get the same chunk
chunk = HeapAlloc(hHeap, 0, size);
printf("chunk: %p\n", chunk);
}
So even if we don’t know where the allocation took place we get back to our first result with twice the same chunk:
chunk: 012A9A40
chunk: 012A9A40
This is really good for a use-after-free and we don’t have to fill all the space in the userblock. What about the overflow ? If we don’t free the chunk, after 0xff allocations, we will get back to the same point in the array, but this chunk will already be in use. At that point the allocation algorithm doesn’t take an other random number and keep trying, it will just take the first next free chunk which follow:
- First we activate the LFH
- Then we allocate the vulnerable chunk
- We allocate 0xff chunks
- We allocate the chunk we want to overflow
It will give us the following code:
#include <Windows.h>
#include <stdio.h>
#include <iostream>
int main()
{
HANDLE hHeap = GetProcessHeap();
char c;
int i = 0;
int size = 0x40;
LPVOID chunk;
// activating the LFH for the size we choose
while (i < 0x10)
{
chunk = HeapAlloc(hHeap, 0, size);
i++;
}
// making the allocation which is vulnerable
chunk = HeapAlloc(hHeap, 0, size);
printf("vulnerable chunk: %p\n", chunk);
// making 0xff allocation for getting back
// to the same point in the RtlpLowFragHeapRandomData
i = 0;
while (i < 0x100 - 1)
{
chunk = HeapAlloc(hHeap, 0, size);
HeapFree(hHeap, 0, chunk);
i++;
}
// allocation we want to overwrite
chunk = HeapAlloc(hHeap, 0, size);
printf("chunk to overwrite: %p\n", chunk);
}
Which will give us the result:
vulnerable chunk: 00559B20
chunk to overwrite: 00559B68
As you can see we have a gap of 8 bytes, those bytes are the size of the _HEAP_ENTRY struct which contains the meta-data of our block.
One of the best advantages of this technic is that we need only one chunk to overwrite and we know which one it is.
Conclusion
We have seen two ways of getting some determinism from the LFH. None of those solutions are perfect. Exploiting a use-after-free with this technic will not be much harder than before if we can have some heap-spray. Overflow is not that easy, even with the second solution we still have a chance to get the last chunk and our two blocks can be separated by an other allocated block. The best way of decreasing the risks is to append is to first fill a subsegment and then use the new one to trigger the overflow.